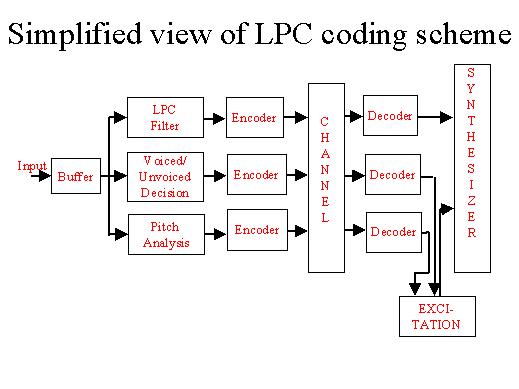
| We can see this simplified diagram which will explain the things. The input speech comes here stored. The samples are stored there, and then you have got the linear predictive coder coding filter, you have got the voice and unvoiced decision and the peach analyses each of these parameters are coded with multiplex transmitted at the receiver. They are decoded and they go to the synthesis filter, the decision regarding the excitation is done from the peach and the voice/unvoice signal given to the excitation system. |
|